 |
| 15:57 GMT, looking south-west |
Tuesday, 31 December 2013
Monday, 30 December 2013

Wednesday, 25 December 2013
his'n'hers carbon sequestration
Labels:
algorithm,
books,
Christmas,
complexity,
computer,
graphics,
mathematics
Here are our Christmas presents to each other. They are books. (There are other types of presents?) The rule is: a book we want, but (probably) would not buy for ourselves. This criterion is almost certainly impossible for the other to determine, so we suggest options to each other.


Tuesday, 24 December 2013
many people would rather fail than change
Evidence-based software engineering? Surely not!
For all my social networking posts, see my Google+ page
For all my social networking posts, see my Google+ page
before and after
We’ve now installed and configured the Christmas tree.
 |
| before and after the makeover |
Monday, 23 December 2013
sequestering carbon, several books at a time XIV
Labels:
books,
complexity,
language
The pre-Christmas arrivals:

Friday, 20 December 2013
vaccinate
Labels:
medicine
I got most vaccines as a child. I do remember getting chicken pox, though. It wasn’t nice.
Growing Up Unvaccinated tells a story more people need to hear.
For all my social networking posts, see my Google+ page
Growing Up Unvaccinated tells a story more people need to hear.
If you think your child’s immune system is strong enough to fight off vaccine-preventable diseases, then it’s strong enough to fight off the tiny amounts of dead or weakened pathogens present in any of the vaccines.
For all my social networking posts, see my Google+ page
Thursday, 19 December 2013
tormenting students
I’ve just used the phrase “mentoring students” in a document. The spell checker doesn’t recognise “mentoring”, and suggests “tormenting” instead.
Hmm. Should I accept the suggestion?
For all my social networking posts, see my Google+ page
Hmm. Should I accept the suggestion?
For all my social networking posts, see my Google+ page
Tuesday, 17 December 2013
compiler shavings
Mike Hoye provides an interesting bit of computing history, plus an Open Source rant.
For all my social networking posts, see my Google+ page
the reason we started using zero-indexed arrays was because it shaved a couple of processor cycles off of a program’s compilation time. Not execution time; compile time.
For all my social networking posts, see my Google+ page
Friday, 13 December 2013
wallpaper your apartment in tinfoil
Labels:
computer
Charlie Stross: Trust Me (I'm a kettle).
Just because you’re paranoid doesn’t mean they aren’t out to get you.
For all my social networking posts, see my Google+ page
Just because you’re paranoid doesn’t mean they aren’t out to get you.
For all my social networking posts, see my Google+ page
Thursday, 12 December 2013
outside looking in
Labels:
astronomy,
moon,
space flight
Something even better than Sagan’s “Pale Blue Dot” for putting things into perspective?
Juno records Earth-Moon orbit.

For all my social networking posts, see my Google+ page
Juno records Earth-Moon orbit.

For all my social networking posts, see my Google+ page
Wednesday, 11 December 2013
Beautiful Soup
In my wanderings, I stumbled across Beautiful Soup, a Python library designed to do just that. I had a little spare time today, so I thought I’d investigate it. A little while reading the documentation (yes, really!), and I’d written and tested the <HR> remover:
from bs4 import BeautifulSoup
def delete_final_hr(soup): changed = False all_tags = soup.find_all(True) if not all_tags: # should never be a tag-less file, but... return changed final_tag = all_tags[-1] if final_tag.name == u'hr': final_tag.decompose() changed = True return changedFind all the tags. If the final one is an <HR>, remove it. And that’s it!
Emboldened by this, I thought of the other change I wanted to make: fix up the ALT/TITLE mess in my IMG tags. In the early days of my website, I was using the ALT tag not only as an actual ALT tag, but also as a stand-in TITLE tag. This was because I’d noticed that the ALT text appeared as hover text in the browser I was then using. I’d thought that was how it was supposed to work, because I didn’t read the documentation (yes, really). Later I discovered the difference, and have recently been using ALT and TITLE properly. Also, I hadn’t bothered to give ALT tags to images that are merely decorative, but I’ve recently learned that they should have ALT="" to be properly skipped by screen readers. So I wanted to fix that, too. So, back to Beautiful Soup, to write an <ALT> modifier.
def update_alt(soup): changed = False all_img = soup.find_all('img') for img in all_img: if 'alt' in img.attrs: if 'title' in img.attrs: # both present, do nothing pass elif img['alt'] != '': # non-empty alt only, copy to title img['title'] = img['alt'] changed = True else: if 'title' in img.attrs: # title only, copy to alt img['alt'] = img['title'] changed = True else: # neither; make an empty alt img['alt'] = '' changed = True return changedFind all the image tags. For each tag, if there’s both an ALT and a TITLE, do nothing; if there’s only a (non-empty) ALT, copy its text into the TITLE; if there’s only a TITLE, copy its text into the ALT; if there’s neither, make an empty ALT. And that’s it!
Easy peasy. Now all I had to do was loop over all the files in the directory structure. Naturally, there’s a library for that.
import os
path = '~susan' for root, dirs, files in os.walk(path): for name in files: if name[-4:] == '.htm': changed = False path_name = os.path.join(root, name) with open(path_name) as file: soup = BeautifulSoup(file) changed = delete_final_hr(soup) or changed changed = update_alt(soup) or changed #write out the modified file, in ascii if changed: with open(path_name, 'wb') as file: file.write(convert_to_entity_names(soup))Walk the directory structure. For each file, if it is an html file, read it into soup, delete the final <HR>, update the ALT/TITLE fields; if this has changed the file, write it back out. And that’s it!
Well, actually, that’s not quite it. The thing that gave me the most grief was the unicode aspects. My first attempt to write the file back out resulted in mangled non-breaking spaces and bullet characters, which were being written out in Unicode, not as html entities. A bit of hunting around on the web led as ever to the invaluable Stack Overflow site, which pointed me in the right direction. After a bit of fiddling, I wrote the adequate, but not totally perfect, solution of:
def convert_to_entity_names(soup): ascii = soup.encode('ascii', 'xmlcharrefreplace') ascii = ascii.replace(' ', ' ') return asciiAnd that really is it!
I ran the code over (a copy of) my website. It looked at 3690 files, opened the 1076 ones of them that were html, and updated 853 of them, all in about 5 seconds.
I love Python (and all its libraries).
I’m not so keen on Unicode.
Tuesday, 10 December 2013
Trello for tablets
Labels:
Trello
I use Trello daily, and now my tablet version no longer looks like a really big phone version. Yay!

For all my social networking posts, see my Google+ page

For all my social networking posts, see my Google+ page
failing to sequester carbon, once a year
Labels:
Christmas
Well, that’s the Christmas cards done for another year.
Being able to print address labels removes the chore aspect, and makes the exercise an enjoyable one of thinking about each of the recipients: who gets which card, and why? (Recipients, please don’t overthink this when you see your card: you get the most appropriate one for you, subject to the invisible-to-you constraints of our available pool of cards.)
Being able to print address labels removes the chore aspect, and makes the exercise an enjoyable one of thinking about each of the recipients: who gets which card, and why? (Recipients, please don’t overthink this when you see your card: you get the most appropriate one for you, subject to the invisible-to-you constraints of our available pool of cards.)
 |
| I can safely say this represents more letters than we produce in the entire rest of the year put together. |
Friday, 6 December 2013


Sunday, 1 December 2013
that's not in the least bit suspicious
Labels:
Bonnie Tyler,
computer,
web
Our internet connection at home travels along the same piece of wet string as does our phone line. (I’m assuming it’s wet string, based on the bandwidth it achieves.) Recently it’s been a bit glitchy, dropping out at random moments. Then the other day I spotted a correlation: it drops out when the phone is in use. This hasn’t always been the case: I’ve been on the phone to support while using my machine, so this is something new.
We spent a while trying to narrow the problem down. Was it answering, being connected, or hanging up the phone that triggered the event? No, it was simply calling the number. Was it one of the filters separating the phone and internet signals? We tried swapping in and out these gadgets. Eventually we had pared the system down to a single filter, with no handsets even connected. Same problem. Either all 7 filters are broken (not totally implausible, they are cheapo dinguses, all over 10 years old), or the problem lies elsewhere.
 What will probably look weird, if not downright suspicious, to anyone monitoring us (not that anyone would do such a thing, obviously...) is what was visible from outside. To see when the network went down, we watched the blinkenlights on the router. To load the network during tests, we downloaded a YouTube video, let it play about halfway through to check the network was stable, then called the landline from a mobile, which stopped the network.
What will probably look weird, if not downright suspicious, to anyone monitoring us (not that anyone would do such a thing, obviously...) is what was visible from outside. To see when the network went down, we watched the blinkenlights on the router. To load the network during tests, we downloaded a YouTube video, let it play about halfway through to check the network was stable, then called the landline from a mobile, which stopped the network.
The result of this is that we downloaded the same YouTube video, and interrupted its download halfway with a call from a mobile, about 20 times. Moreover, because the network connection dropped out, it would re-establish with a different IP address each time, as provided by our ISP.
Oh, and what was this ultra-suspicious video? Bonnie Tyler’s Total Eclipse of the Heart, obviously.

The result of this is that we downloaded the same YouTube video, and interrupted its download halfway with a call from a mobile, about 20 times. Moreover, because the network connection dropped out, it would re-establish with a different IP address each time, as provided by our ISP.
Oh, and what was this ultra-suspicious video? Bonnie Tyler’s Total Eclipse of the Heart, obviously.
Saturday, 30 November 2013
November leaves
November has been so mild that many of the trees still have their leaves.
It's not all leaves.
 |
| apple tree |
 |
| maple |
That's not to say there aren't many leaves on the ground, and in the water.
 |
| leaves in the rill |
 |
| leaves surrounded |
It's not all leaves.
 |
| this tiny mushroom in the path has caught a thread |
Friday, 29 November 2013
Venus
Venus is very bright tonight.
Once I had checked it wasn’t an aeroplane, I was sure it was Venus. But I thought I’d check with Google Sky map; it’s always nice to have an excuse to play with that app. I fired it up, and pointed my phone at the bright light.

No, I don’t think so. And not just because I knew I wasn’t looking south…
I waited a few seconds, until the orientation sensor kicked in properly, and the image slewed round to show:

That’s better!
 |
| 16:52 GMT, looking south west; unretouched phone photo |
No, I don’t think so. And not just because I knew I wasn’t looking south…
I waited a few seconds, until the orientation sensor kicked in properly, and the image slewed round to show:
That’s better!
Wednesday, 27 November 2013

Monday, 25 November 2013
graphics can have a grammar, too
Labels:
algorithm,
graphics,
python,
statistics
My random walk through web space led me to the Python library bokeh. This led me to Leland Wilkinson’s The Grammar of Graphics, which I will almost certainly be buying shortly, after skimming through the Google Books version.
Meanwhile, I found this very nice partial review of it, which has links to other articles and books (that I will almost certainly be buying shortly...) It also has some excellent acerbic comments on the Excel Chart Wizard!
For all my social networking posts, see my Google+ page
Meanwhile, I found this very nice partial review of it, which has links to other articles and books (that I will almost certainly be buying shortly...) It also has some excellent acerbic comments on the Excel Chart Wizard!
 |
| This is NOT the approach that Wilkinson takes. |
For all my social networking posts, see my Google+ page
Sunday, 24 November 2013
The Five(ish) Doctors Reboot
Labels:
Doctor Who
And for those who wanted more Original Doctors in their anniversary celebrations, try this! (And wait until the end of the first credits, too.)

For all my social networking posts, see my Google+ page

For all my social networking posts, see my Google+ page
Coal Hill School
Labels:
Doctor Who
I got that the beginning of The Day of the Doctor was set in the actual school that Susan went to in the very first episode, and that was used for a nod back to 1963 in the 1988 story Remembrance of the Daleks, but I missed this tidbit:
For all my social networking posts, see my Google+ page
We got just long enough a look at the sign with the school’s name for me to notice that the Governor of its Board of Directors is one “I. Chesterton”.Sweet.
For all my social networking posts, see my Google+ page
Saturday, 23 November 2013
Spoilers!
Labels:
Doctor Who

I had been carefully managing my expectations, because The Day of the Doctor couldn’t possibly live up to the hype, excitement, and full weight of the 50 year history, could it?
Yes it could.
 |
| the 11 Doctors – but actually it should be 12! |
We now have a continuous timeline of regenerations, filling in the gap between McGann and Ecclestone. Which leads to the question: what is the official numbering now? (That certainly promises oodles of fun for pedants in future pub quizzes!) And the problem to do with the 13th regeneration has been acknowledged, so we have that to look forward to.
But most important of all, it is a great story, playing on the existence of time travel and time paradoxes, examining the great Time War and the Doctor’s dreadful role in it. It is a marvelous episode, full of fun, pathos, wit, momentous moral decisions, and gorgeous nods to the 50 year history, from the cheeky opening shot in Totter’s Lane to the epic final battle around Gallifrey. Tennant and Smith work excellently together, playing off each other. In a clever twist it is these somewhat childish later Doctors who are the living with the memory of the terrible deed they have done, while the older, more adult Doctor (Hurt) has not yet committed the act that will scar the Doctor throughout his future regenerations.
 |
| Three Doctors – the Daleks don’t stand a chance! |
Who would have thought, 50 years ago today, that the future would hold something like this?
So, I wonder: what the diamond anniversary will hold?
found it!
Labels:
Doctor Who
After trawling through more newsagents than I would like to admit, we now have the full set of Radio Times covers:
 |
| Matt Smith found at last |
with apologies to The Four Seasons
Labels:
Doctor Who,
music
November, 1963 (Oh, What A Night)
Oh, what a night
Late November, back in ’63
Was a very special time for me
As I remember, what a fright
Oh, what a night
You know, we never got know his name
But life was never gonna be the same
What a Doctor, what a sight
Oh, I
I got a funny feeling when he walked through the door
Oh, my
That TARDIS, inside was so much more
Oh, what a sight
Materialising: mesmerizing me
Who was everything I dreamed it’d be
So SFnal, what a night
And I felt a rush when the TARDIS sounded thunder
Spinning its light around and sparking my sensawunda
Oh, what a night
Oh, I
I got a funny feeling when he walked through the door
Oh, my
That TARDIS, inside was so much more
Oh, what a night
Why’d it take so long to do what’s right?
Beeb was wrong, but now it’s seen the light
What a Doctor, what a night
And I felt a rush when the TARDIS sounded thunder
Spinning its light around and sparking my sensawunda
Oh, what a night (doo de-do, doo de-do, doo de-do, dee di-di)
golden anniversary anticipation
Labels:
Doctor Who
We have a small collection of small daleks

standing at the foot of our smaller collection of full sized daleks.

We don’t collect only daleks, of course. To celebrate the 50th anniversary, this week’s issue of the Radio Times has 12 different covers.
These will be added to our collection of other Who-covered Radio Times.
And now, we have to wait until this evening for The Day of the Doctor, which we will be watching at home on the TV in 2D, the way it is meant to be seen! We have, of course, already watched the webisode Night of the Doctor, which provides an crucial insight into the timeline, and the number line.

standing at the foot of our smaller collection of full sized daleks.

We don’t collect only daleks, of course. To celebrate the 50th anniversary, this week’s issue of the Radio Times has 12 different covers.
 |
| We have 11 of the 12 different covers this week. Matt Smith had sold out. |
These will be added to our collection of other Who-covered Radio Times.
 |
| Row 2 has 4 covers from the 40th anniversary, which form a montage. |
And now, we have to wait until this evening for The Day of the Doctor, which we will be watching at home on the TV in 2D, the way it is meant to be seen! We have, of course, already watched the webisode Night of the Doctor, which provides an crucial insight into the timeline, and the number line.
Friday, 22 November 2013
prediction shouldn't be this difficult
I have previously noted the inaccuracy of some computer predictions. Tonight I observed how it also applies to cars.
As I started my trip, the GPS said the journey would take 2 hours 20 minutes, and the car instrument panel claimed I had 205 miles until an empty tank.
50 miles, and one hour, later, the GPS said the remaining journey would take 2 hours 5 minutes; more bizarrely still, the car instrument panel claimed I now had 215 miles until an empty tank.
So, it seems that the car thought I had taken 15 minutes to travel 10 miles backwards?
As I started my trip, the GPS said the journey would take 2 hours 20 minutes, and the car instrument panel claimed I had 205 miles until an empty tank.
50 miles, and one hour, later, the GPS said the remaining journey would take 2 hours 5 minutes; more bizarrely still, the car instrument panel claimed I now had 215 miles until an empty tank.
So, it seems that the car thought I had taken 15 minutes to travel 10 miles backwards?
sequestering carbon, several books at a time XIII
Labels:
books,
science fiction
The latest additions:


Thursday, 21 November 2013
600 and falling
Labels:
mathematics
 |
| Terrence Tao |
tl;dr: It’s down to 600.
For all my social networking posts, see my Google+ page
this is what happens when you give Computer Scientists access to piped chocolate
We had a Children in Need quiz night at work yesterday. One round was to decorate a cake. Our team (The Flying Robots) felt that a fractal, with its infinite chocolate complexity, should be a sure winner.
The judges, for some unfathomable reason, preferred another:
Okay, maybe we weren’t taking it that seriously…
Thanks to Richard Hawkins, Gary Plumbridge, Simon Poulding, Ian Gray, Ed Powely and Sarah Christmas for some fiendish questions, as well as lovely cake!
 |
| Sierpinski cake |
 |
| double decker artistry |
Thanks to Richard Hawkins, Gary Plumbridge, Simon Poulding, Ian Gray, Ed Powely and Sarah Christmas for some fiendish questions, as well as lovely cake!
Tuesday, 19 November 2013
autumn trees
Walking over to a meeting on campus, I spotted the sun low on the magnificent tree in front of the library.

Magnificent autumn colour (and it looker oranger in real life than in the pic). Then a few steps further on I saw another tree catching the light:

It was also brighter in real life than here.
Just, wow!

Magnificent autumn colour (and it looker oranger in real life than in the pic). Then a few steps further on I saw another tree catching the light:

It was also brighter in real life than here.
Just, wow!
Monday, 18 November 2013
python's lunchbox
A love letter to Python. The last footnote mentions bokeh, a python library supporting the Grammar of Graphics. I know what I'm going to be playing with this weekend!
For all my social networking posts, see my Google+ page
For all my social networking posts, see my Google+ page
Sunday, 17 November 2013
representations, permutations, visualisations
A recent advance has been the introduction of “evo-devo” algorithms. (I’m putting all this biological terminology in scare quotes, because by the time the relevant process has been translated into a computer algorithm, it is so far removed from its biological inspiration as to make a biologist wince, or even exclaim in outrage.) Evo-devo puts a distance between the genome (the representation that gets mutated) and the “phenotype” (the representation that gets selected based on fitness). This can help the algorithm’s performance, by allowing simple easily mutatable genomes develop into complex structured phenotypes.
A colleague of mine at York, Julian Miller, is the inventor of such an algorithm, Cartesian Genetic Programming (CGP). The genome is a string of numbers (numbers are easy to mutate a little bit). The string is then interpreted as a network phenotype. The network itself has inputs and outputs, so is a form of program.
Now, let’s consider permutations. A permutation of the numbers 1 to N is these numbers in some specific order. So the permutations of 1 to 3 are: (1,2,3), (1,3,2), (2,1,3), (2,3,1), (3,1,2), (3,2,1). A string of length N has N! (N factorial) permutations. N! grows very fast; while 5! = 120, 10! = 3,628,800, and 100! > 10157.
Permutations are common in computer science. One classic use is in the Travelling Salesman Problem: given a bunch of N cities, find the shortest path through all of them. That is, find the permutation of 1 to N that gives the shortest path. Given there are N! such permutations, clearly we don’t want to try them all. Although exact algorithms that are essentially more efficient than trying all possibilities aren’t known (and it is strongly suspected that there aren’t any), there are algorithms that come up with very good approximate (nearly shortest path) answers most of the time. EAs are one such class of algorithms: breed for fitter (shorter) paths.
Permutations as genomes are a bit tricky, though. A permutation has structure: it must contain all the numbers from 1 to N, and each only once. So you can’t mutate a single entry: you have to swap two entries, or do something else that maintains the permutation structure. “Crossover” is even harder: how do you take half of one permutation, half of another, and combine them into a valid permutation? There are various techniques, but they are not very pretty.
Using an evo-devo approach to generate a permutation seems even harder: how do you ensure that your developed system is a valid permutation? So, for example, with CGP we can have a list of outputs, but how do we ensure that this list is a valid permutation? (Having a single output that is already a permutation merely moves the problem back inside the network somewhere.)
We need a further representation and development step that is guaranteed to produce a permutation. Rather than try to get the network to produce a permutation immediately, let’s break it down into two steps: the network produces a list of numbers, then that list has to go through a further interpretation step to form a permutation. Julian came up with an idea of how to do this: given a list of (say) real numbers (easy to produce with CGP), just sort them into ascending order. The correspondingly sorted list of the indexes gives the required permutation. Voilà!
 |
| A string of numbers is interpreted as a network, which outputs a real vector, which when sorted yields a permutation |
What is happening here is easy to visualise using a technique called parallel coordinates. A list of N real numbers can be thought of as a vector in N-D space. But N-D space is hard to visualise if N > 3. (I find it pretty hard to visualise even when N = 3.)
 |
| It’s hard to visualise a lot of dimensions this way |
Parallel coordinates do what it says in the name: instead of drawing the N dimensions orthogonal to each other (rapidly running out of ways to do this in our 3D physical space), draw them parallel to each other. It’s easy to draw lots of parallel lines. Now plot the N-D point (x1,x2,...xN) as follows: plot the point x1 on axis 1, the point x2 on axis 2, and so on, then joint these points together with a line. The line in the parallel coordinate plot represents the point in N-D space.
 |
| parallel coordinates view of a single N-D point |
We can use these parallel coordinated to visualise how a vector of real numbers can represent a permutation by its components being sorted into ascending order.
 |
| (top) a vector of 20 real numbers, a 20-D point, drawn in parallel coordinates; (bottom) the same vector, with the parallel axes ordered so that the components are in increasing order: the sorted axis indexes are the permutation represented by the N-D point. |
The Python/numpy code that generated these plots is:
N = 20
P = range(N) # indexes
V = rand(N) # random vector
# plot unsorted vector
for dim in range(N):
ax1.plot([dim, dim], [0, 1], '0.5', linewidth=0.25)
ax1.text(dim, -0.2, str(P[dim]), ha='center', fontsize=32)
ax1.plot(range(N), V, '.k', markersize=20)
ax1.plot(range(N), V, 'k')
# sort, and plot sorted vector
P = argsort(V) # sort indexes
V = sort(V) # sort vector (for plotting)
for dim in range(N):
ax2.plot([dim, dim], [0, 1], '0.5', linewidth=0.25)
ax2.text(dim, -0.2, str(P[dim]), ha='center', fontsize=32)
ax2.plot(range(N), V, '.k', markersize=20)
ax2.plot(range(N), V, 'k')
Note that the code that generates the permutation is the single line P = argsort(V): the rest is just plotting code.Here I started from a random vector, rather than the non-random output of some CGP network. Sorting a random vector is one way to construct a random permutation, but as far as Julian and I can tell from the literature, this CGP use for representing evolved, non-random permutations isn’t standard. Julian has been using it for several years in his module on evolutionary algorithms, and will be publishing a paper on some results next year.
Friday, 15 November 2013
questioning scientists
I don’t watch Question Time, but signed this petition anyway. If they respond positively, I might even start watching!
For all my social networking posts, see my Google+ page
 |
| Question Time representation |
For all my social networking posts, see my Google+ page
Thursday, 14 November 2013
Wednesday, 13 November 2013

Tuesday, 12 November 2013
afternoon sunset
The view at 4:30pm, and it’s still over a month to the shortest day!
 |
| 16:30 GMT, looking west |
Saturday, 9 November 2013
the old and the new
Labels:
Chicheley Hall,
computer,
conference,
garden,
history,
research,
science
I’m just back from a 2 day residential Theo Murphy scientific workshop held in the Royal Society’s Kavli Centre at Chicheley Hall. It’s my first visit there, and I can certainly recommend it as a marvellous venue for a workshop: great facilities, marvelous food, and friendly, efficient staff. The science was great fun: I learned lots of new things, discovered links between seemingly diverse areas, and had interesting discussions over food and coffee. I’m buzzing with ideas, which is the whole point!
I did the usual “photograph from my bedroom window” thing, which had a somewhat different from usual view:
Oh, and then I took a photo from the other window in my bedroom:
Blissful. I found an amusing view from the window half way down the main stairs:

A lovely formal garden, with lawns, paths, clipped bushes and trees, and, just visible at the vanishing point of the path … a wind farm! The old and the new collide.
I did the usual “photograph from my bedroom window” thing, which had a somewhat different from usual view:
 |
| first day of the workshop, view due east, into the rising sun |
Oh, and then I took a photo from the other window in my bedroom:
 |
| first day of the workshop, view due south |

A lovely formal garden, with lawns, paths, clipped bushes and trees, and, just visible at the vanishing point of the path … a wind farm! The old and the new collide.

Monday, 4 November 2013
a deeply imbedded myth
Labels:
science
How many cell types are there? Another myth laid bare...
(I also recommend the referenced Fox Terrier paper.)
For all my social networking posts, see my Google+ page
(I also recommend the referenced Fox Terrier paper.)
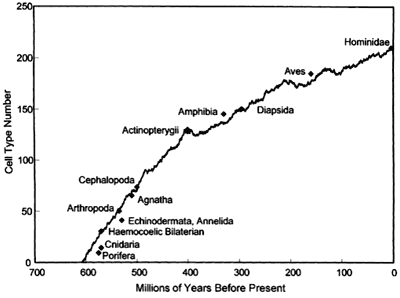 |
| There is no data supporting this kind of chart. |
this number and imaginary trend in cell type complexity are derived entirely from an otherwise obscure and rarely cited 60 year old review paper that contained no original data on the problem; the values are all guesswork, estimates from the number of cell types listed in histology textbooks.
For all my social networking posts, see my Google+ page
Subscribe to:
Comments (Atom)