The latest batch, comprising his'n'hers birthday presents.

The latest batch, comprising his'n'hers birthday presents.
The latest batch:




from pywinauto.application import Application
def backup_ace_money(pwd,file_name):
# Launch the application
app = Application().start(r'C:\Program Files (x86)\AceMoney\AceMoney.exe', timeout=10)
# Enter password, click OK
pwd_dlg = app.window(title='Enter password')
pwd_dlg.Edit.type_keys(pwd)
pwd_dlg.OKButton.click()
# Select File > SaveAs in main window
main_dlg = app.top_window()
main_dlg.menu_select('File -> Save As...')
# Enter the file name in the Save menu, and click Save
save_dlg = app.window(title='Save As')
save_dlg.SaveAsComboBox1.type_keys(file_name)
save_dlg.SaveButton.click()
# Exit AceMoney
main_dlg.close()The only (hah!) difficult bit was discovering the name of the box to type the file name into. (I confess that discovering the mere existence of the menu_select() function took me more time, and extreme muttering, than it should have.) The print_control_identifiers() function was indispensable for finding the name of the relevant control, but the great advantage is you can access by (relatively robust) name, not (incredibly fragile) screen position.
So, a couple of hours and 10 lines of code later, this task has now been automated.
And now I'm thinking about what to automate next.

I was writing some Python code today, and I had some logic best served by a case statement. I remembered that Python doesn't have a case statement, but I decided to google to see if there was a suitably pythonic pattern I should use instead.
Aha! Python v3.10 introduced a case statement, and I'm currently using v3.13. Excellent. I scanned the syntax, then added the relevant lines to my code.
After I'd finished that bit of coding, I went and read the official Python tutorial. Of course, Python being Python, its 'case' statement is actually a very sophisticated and powerful 'structural pattern matching' statement. I might have some fun with this...
So, every day in every way, at least Python is getting better and better.
The latest batch, comprising his'n'hers birthday presents.

The latest batch:

The latest batch:

The latest batch:

Our new paper published recently:
Penelope Faulkner Rainford, Angelika Sebald, Susan Stepney.
MetaChem: An algebraic framework for Artificial Chemistries
Artificial Life Journal, 26(2):153–195, 2020
Abstract: We introduce MetaChem, a language for representing and implementing artificial chemistries. We motivate the need for modularization and standardization in representation of artificial chemistries. We describe a mathematical formalism for Static Graph MetaChem, a static-graph-based system. MetaChem supports different levels of description, and has a formal description; we illustrate these using StringCatChem, a toy artificial chemistry. We describe two existing artificial chemistries—Jordan Algebra AChem and Swarm Chemistry—in MetaChem, and demonstrate how they can be combined in several different configurations by using a MetaChem environmental link. MetaChem provides a route to standardization, reuse, and composition of artificial chemistries and their tools.


from fractions import Fraction as frac
found = set()
for denom in range(1,15):
for num in range(1,denom):
q = frac(num,denom)
xq = (1-q*q)/(1+q*q)
yq = 2*q/(1+q*q)
n = xq.denominator
triple = sorted([int(xq*n), int(yq*n), n])
if triple[0] not in found:
print( '{0:<7} ({1:^7}, {2:^7}) {3}'.format(str(q),str(xq),str(yq),triple) )
found.add(triple[0])
1/2 ( 3/5 , 4/5 ) [3, 4, 5] 2/3 ( 5/13 , 12/13 ) [5, 12, 13] 1/4 ( 15/17 , 8/17 ) [8, 15, 17] 3/4 ( 7/25 , 24/25 ) [7, 24, 25] 2/5 ( 21/29 , 20/29 ) [20, 21, 29] 4/5 ( 9/41 , 40/41 ) [9, 40, 41] 1/6 ( 35/37 , 12/37 ) [12, 35, 37] 5/6 ( 11/61 , 60/61 ) [11, 60, 61] 2/7 ( 45/53 , 28/53 ) [28, 45, 53] 4/7 ( 33/65 , 56/65 ) [33, 56, 65] 6/7 ( 13/85 , 84/85 ) [13, 84, 85] 1/8 ( 63/65 , 16/65 ) [16, 63, 65] 3/8 ( 55/73 , 48/73 ) [48, 55, 73] 5/8 ( 39/89 , 80/89 ) [39, 80, 89] 7/8 (15/113 , 112/113) [15, 112, 113] 2/9 ( 77/85 , 36/85 ) [36, 77, 85] 4/9 ( 65/97 , 72/97 ) [65, 72, 97] 8/9 (17/145 , 144/145) [17, 144, 145] 3/10 (91/109 , 60/109 ) [60, 91, 109] 7/10 (51/149 , 140/149) [51, 140, 149] 9/10 (19/181 , 180/181) [19, 180, 181] 2/11 (117/125, 44/125 ) [44, 117, 125] 4/11 (105/137, 88/137 ) [88, 105, 137] 6/11 (85/157 , 132/157) [85, 132, 157] 8/11 (57/185 , 176/185) [57, 176, 185] 10/11 (21/221 , 220/221) [21, 220, 221] 1/12 (143/145, 24/145 ) [24, 143, 145] 5/12 (119/169, 120/169) [119, 120, 169] 7/12 (95/193 , 168/193) [95, 168, 193] 11/12 (23/265 , 264/265) [23, 264, 265] 2/13 (165/173, 52/173 ) [52, 165, 173] 4/13 (153/185, 104/185) [104, 153, 185] 6/13 (133/205, 156/205) [133, 156, 205] 8/13 (105/233, 208/233) [105, 208, 233] 10/13 (69/269 , 260/269) [69, 260, 269] 12/13 (25/313 , 312/313) [25, 312, 313] 3/14 (187/205, 84/205 ) [84, 187, 205] 5/14 (171/221, 140/221) [140, 171, 221] 9/14 (115/277, 252/277) [115, 252, 277] 11/14 (75/317 , 308/317) [75, 308, 317] 13/14 (27/365 , 364/365) [27, 364, 365]and larger values are readily calculated, such as:
500/1001 (752001/1252001, 1001000/1252001) [752001, 1001000, 1252001]
 |
| 42 million randomly chosen values of \(c\) |

import numpy as np
import matplotlib.pyplot as plt
IMSIZE = 2048 # image width/height
ITER = 1000
def mandelbrot(c, k=2):
# c = position, complex; k = power, real
z = c
traj = [c]
for i in range(1, ITER):
z = z ** k + c
traj += [z]
if abs(z) > 2: # escapes
return traj, []
return [], traj
def updateimage(img, traj):
for z in traj:
xt, yt = z.real, z.imag
ixt, iyt = int((2+xt)*IMSIZE/4), int((2-yt)*IMSIZE/4)
# check traj still in plot area
if 0 <= ixt and ixt < IMSIZE and 0 <= iyt and iyt < IMSIZE:
img[ixt,iyt] += 1
# start with value 1 because take logs later
buddha = np.ones([IMSIZE,IMSIZE])
abuddha = np.ones([IMSIZE,IMSIZE])
for i in range(IMSIZE*IMSIZE*10):
z = np.complex(np.random.uniform()*4-2, np.random.uniform()*4-2)
traj, traja = mandelbrot(z, k)
updateimage(buddha,traj)
updateimage(abuddha,traja)
buddha = np.square(np.log(buddha)) # to extend small numbers
abuddha = np.log(abuddha) # to extend small numbers
plt.axis('off')
plt.imshow(buddha, cmap='cubehelix')
plt.show()
plt.imshow(abuddha, cmap='cubehelix')
plt.show()
These plots are more are computationally expensive to produce than the plain Mandelbrot set plots: it is good to have a large number of initial points, and a long trajectory run. There are some beautifully detailed figures on the Wikipedia page. |
| \(k = 2.5\), the "piggy-brot" |
 |
| \(c = -0.5+0.5i\), a point well inside the Mandelbrot set |
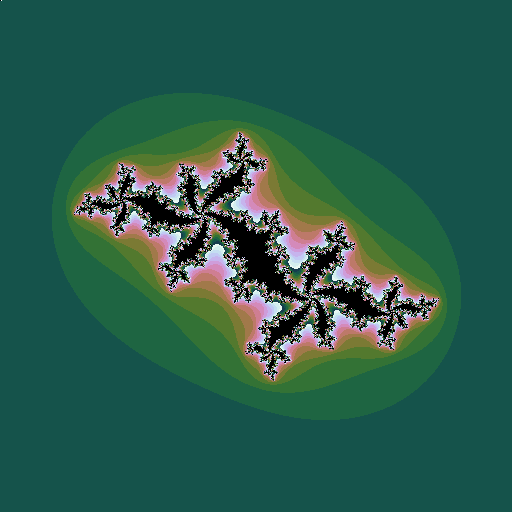 |
| \(c = -0.5+0.6i\), a point just inside the Mandelbrot set |
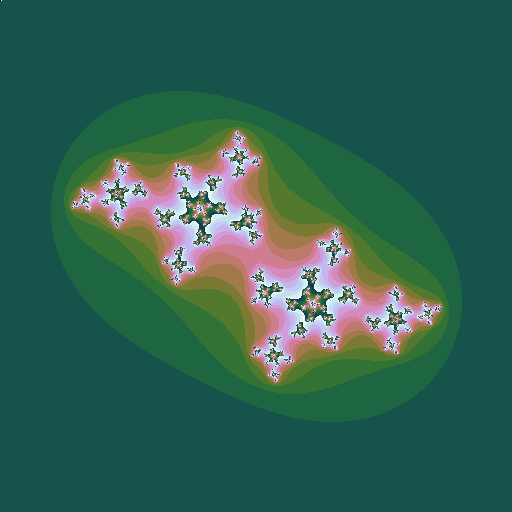 |
| \(c = -0.5+0.7i\), a point outside the Mandelbrot set |
 |
| Julia sets mapping out the Mandelbrot set |
 |
| \(k=3, c = -0.5+0.598i\) |
 |
| \(k=4, c = -0.5+0.444i\) |
import numpy as np
import matplotlib.pyplot as plt
IMSIZE = 512 # image width/height
ITER = 256
def julia(z, c, k=2):
# z = position, complex ; c = constant, complex; k = power, real
z = z
for i in range(1, ITER):
z = z ** k + c
if abs(z) > 2:
return 4 + i % 16 #16 colours
return 0
julie = np.zeros([IMSIZE,IMSIZE])
c = np.complex(-0.5,0.5)
for ix in range(IMSIZE):
x = 4 * ix / IMSIZE - 2
for iy in range(IMSIZE):
y = 2 - 4 * iy / IMSIZE
julie[iy,ix] = julia(np.complex(x,y), c, 5)
julie[0,0]=0 # kludge to get uniform colour maps for all plots
plt.axis('off')
plt.imshow(julie, cmap='cubehelix')
plt.show()

 |
| iterating \(z^4 + c\) |
 |
| iterating \(z^{2.5} + c\) |
 |
| \(k = 1 .. 6\), step \(0.05\) |
import numpy as np
import matplotlib.pyplot as plt
IMSIZE = 512 # image width/height
ITER = 256
def mandelbrot(c, k=2):
# c = position, complex; # k = power, real
z = c
for i in range(1, ITER):
if abs(z) > 2:
return 4 + i % 16 #16 colours
z = z ** k + c
return 0
mandy = np.zeros([IMSIZE,IMSIZE])
for ix in range(IMSIZE):
x = 4 * ix / IMSIZE - 2
for iy in range(IMSIZE):
y = 2 - 4 * iy / IMSIZE
mandy[iy,ix] = mandelbrot(np.complex(x,y), k)
plt.axis('off')
plt.imshow(mandy, cmap='cubehelix')
plt.show()
And there's more. But that's for another post.



def setup():
size(1200, 800)
noStroke()
background(250)
def draw():
cre,cim = random(-2.4,1.3),random(-1.6,1.6)
x,y = 0,0
n = 0
while x*x + y*y < 4 and n < 8 :
n += 1
x,y = x*x - y*y + cre, 2*x*y + cim
fill((n+2)*41 %256, (256-n*101) % 256, n*71 %256)
r = random(2,15)
circle(cre*height/4+width/2,cim*height/4+height/2,r)













